Pretraining and Transfer Learning¶
Sources Transfer Learning cs231n @ Stanford: In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.
These two major transfer learning scenarios look as follows:
CNN as fixed feature extractor:
Take a CNN pretrained on ImageNet
Remove the last fully-connected layer (this layer’s outputs are the 1000 class scores for a different task like ImageNet).
Treat the rest of the CNN as a fixed feature extractor for the new dataset.
This last fully connected layer is replaced with a new one with random weights and only this layer is trained:
Freeze the weights for all of the network except that of the final fully connected layer.
Fine-tuning all the layers of the CNN:
Same procedure, but do not freeze the weights of the CNN, by continuing the backpropagation on the new task.
from torch.optim import lr_scheduler
import torch.optim as optim
import torch.nn as nn
import torch
import os
import numpy as np
# Plot
import matplotlib.pyplot as plt
import seaborn as sns
# Plot parameters
plt.style.use('seaborn-v0_8-whitegrid')
fig_w, fig_h = plt.rcParams.get('figure.figsize')
plt.rcParams['figure.figsize'] = (fig_w, fig_h * .5)
# Device configuration
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# device = 'cpu' # Force CPU
print(device)
cpu
Training function¶
See train_val_model function.
from pystatsml.dl_utils import train_val_model
Classification: CIFAR-10 dataset with 10 classes¶
Load CIFAR-10 dataset CIFAR-10 Loader
from pystatsml.datasets import load_cifar10_pytorch
dataloaders, _ = load_cifar10_pytorch(
batch_size_train=100, batch_size_test=100)
# Info about the dataset
D_in = np.prod(dataloaders["train"].dataset.data.shape[1:])
D_out = len(set(dataloaders["train"].dataset.targets))
print("Datasets shape:", {
x: dataloaders[x].dataset.data.shape for x in dataloaders.keys()})
print("N input features:", D_in, "N output:", D_out)
Files already downloaded and verified
Files already downloaded and verified
Datasets shape: {'train': (50000, 32, 32, 3), 'test': (10000, 32, 32, 3)}
N input features: 3072 N output: 10
Finetuning the convnet¶
Load a pretrained model and reset final fully connected layer.
SGD optimizer.
from torchvision.models import resnet18, ResNet18_Weights
model_ft = resnet18(weights=ResNet18_Weights.DEFAULT)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 10.
model_ft.fc = nn.Linear(num_ftrs, D_out)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model, losses, accuracies = \
train_val_model(model_ft, criterion, optimizer_ft,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=5,
log_interval=5)
epochs = np.arange(len(losses['train']))
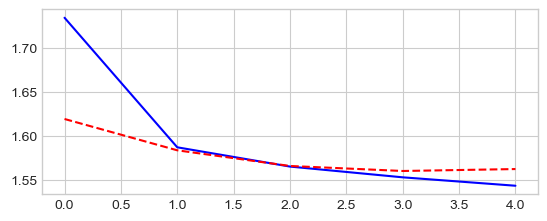
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['test'], '--r')
Epoch 0/4
----------
train Loss: 1.1057 Acc: 61.23%
test Loss: 0.7816 Acc: 72.62%
Training complete in 31m 43s
Best val Acc: 78.90%
Adam optimizer
model_ft = resnet18(weights=ResNet18_Weights.DEFAULT)
# model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 10.
model_ft.fc = nn.Linear(num_ftrs, D_out)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = torch.optim.Adam(model_ft.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model, losses, accuracies = \
train_val_model(model_ft, criterion, optimizer_ft,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=5,
log_interval=5)
epochs = np.arange(len(losses['train']))
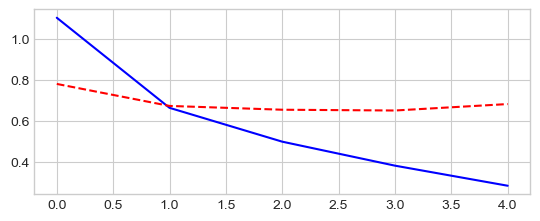
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['test'], '--r')
Epoch 0/4
----------
train Loss: 0.9112 Acc: 69.17%
test Loss: 0.7230 Acc: 75.18%
Training complete in 31m 9s
Best val Acc: 80.49%
ResNet as a feature extractor¶
Freeze all the network except the final layer:
requires_grad == False to freeze the parameters so that the
gradients are not computed in backward().
model_conv = resnet18(weights=ResNet18_Weights.DEFAULT)
# model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, D_out)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model, losses, accuracies = \
train_val_model(model_conv, criterion, optimizer_conv,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=5,
log_interval=5)
epochs = np.arange(len(losses['train']))
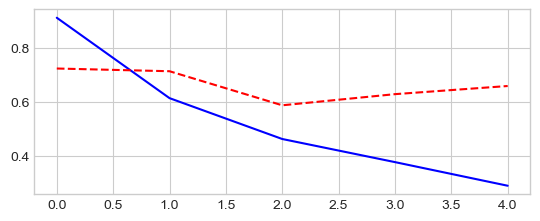
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['test'], '--r')
Epoch 0/4
----------
train Loss: 1.8177 Acc: 36.64%
test Loss: 1.6591 Acc: 42.88%
Training complete in 8m 6s
Best val Acc: 46.44%
Adam optimizer
model_conv = resnet18(weights=ResNet18_Weights.DEFAULT)
# model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, D_out)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.Adam(model_conv.fc.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model, losses, accuracies = \
train_val_model(model_conv, criterion, optimizer_conv,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=5,
log_interval=5)
epochs = np.arange(len(losses['train']))
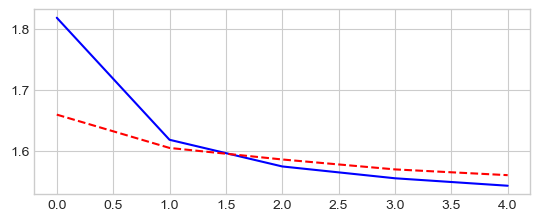
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['test'], '--r')
Epoch 0/4
----------
train Loss: 1.7337 Acc: 39.62%
test Loss: 1.6193 Acc: 44.09%
Training complete in 7m 59s
Best val Acc: 46.43%