Transfer Learning Tutorial¶
Sources:
Quote cs231n @ Stanford:
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.
These two major transfer learning scenarios look as follows:
ConvNet as fixed feature extractor:
Take a ConvNet pretrained on ImageNet,
Remove the last fully-connected layer (this layer’s outputs are the 1000 class scores for a different task like ImageNet)
Treat the rest of the ConvNet as a fixed feature extractor for the new dataset.
In practice:
Freeze the weights for all of the network except that of the final fully connected layer. This last fully connected layer is replaced with a new one with random weights and only this layer is trained.
Finetuning the convnet:
fine-tune the weights of the pretrained network by continuing the backpropagation. It is possible to fine-tune all the layers of the ConvNet
Instead of random initializaion, we initialize the network with a pretrained network, like the one that is trained on imagenet 1000 dataset. Rest of the training looks as usual.
%matplotlib inline
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
import torchvision.transforms as transforms
from torchvision import models
#
from pathlib import Path
import matplotlib.pyplot as plt
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = 'cpu' # Force CPU
Training function¶
Combine train and test/validation into a single function.
Now, let’s write a general function to train a model. Here, we will illustrate:
Scheduling the learning rate
Saving the best model
In the following, parameter scheduler is an LR scheduler object from
torch.optim.lr_scheduler.
# %load train_val_model.py
import numpy as np
import torch
import time
import copy
def train_val_model(model, criterion, optimizer, dataloaders, num_epochs=25,
scheduler=None, log_interval=None):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
# Store losses and accuracies accross epochs
losses, accuracies = dict(train=[], val=[]), dict(train=[], val=[])
for epoch in range(num_epochs):
if log_interval is not None and epoch % log_interval == 0:
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
nsamples = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
nsamples += inputs.shape[0]
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if scheduler is not None and phase == 'train':
scheduler.step()
#nsamples = dataloaders[phase].dataset.data.shape[0]
epoch_loss = running_loss / nsamples
epoch_acc = running_corrects.double() / nsamples
losses[phase].append(epoch_loss)
accuracies[phase].append(epoch_acc)
if log_interval is not None and epoch % log_interval == 0:
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if log_interval is not None and epoch % log_interval == 0:
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, losses, accuracies
CIFAR-10 dataset¶
WD = os.path.join(Path.home(), "data", "pystatml", "dl_cifar10_pytorch")
os.makedirs(WD, exist_ok=True)
os.chdir(WD)
print("Working dir is:", os.getcwd())
os.makedirs("data", exist_ok=True)
os.makedirs("models", exist_ok=True)
# Image preprocessing modules
transform = transforms.Compose([
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])
# CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='data/',
train=True,
transform=transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(root='data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False)
# Put together train and val
dataloaders = dict(train=train_loader, val=val_loader)
# Info about the dataset
data_shape = dataloaders["train"].dataset.data.shape[1:]
D_in = np.prod(data_shape)
D_out = len(set(dataloaders["train"].dataset.targets))
print("Datasets shape", {x: dataloaders[x].dataset.data.shape for x in ['train', 'val']})
print("N input features", D_in, "N output", D_out)
Working dir is: /home/ed203246/data/pystatml/dl_cifar10_pytorch
Files already downloaded and verified
Datasets shape {'train': (50000, 32, 32, 3), 'val': (10000, 32, 32, 3)}
N input features 3072 N output 10
Finetuning the convnet¶
Load a pretrained model and reset final fully connected layer.
SGD optimizer.
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 10.
model_ft.fc = nn.Linear(num_ftrs, D_out)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
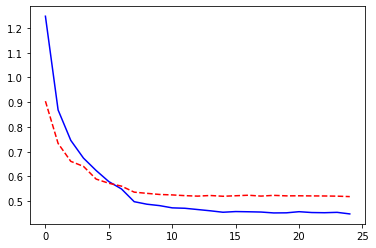
model, losses, accuracies = train_val_model(model_ft, criterion, optimizer_ft,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=25, log_interval=5)
epochs = np.arange(len(losses['train']))
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['val'], '--r')
Epoch 0/24
----------
train Loss: 1.2476 Acc: 0.5593
val Loss: 0.9043 Acc: 0.6818
Epoch 5/24
----------
train Loss: 0.5791 Acc: 0.7978
val Loss: 0.5725 Acc: 0.8035
Epoch 10/24
----------
train Loss: 0.4731 Acc: 0.8351
val Loss: 0.5254 Acc: 0.8217
Epoch 15/24
----------
train Loss: 0.4581 Acc: 0.8388
val Loss: 0.5220 Acc: 0.8226
Epoch 20/24
----------
train Loss: 0.4575 Acc: 0.8394
val Loss: 0.5218 Acc: 0.8236
Training complete in 138m 32s
Best val Acc: 0.825100
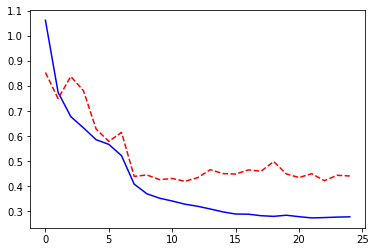
Adam optimizer
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 10.
model_ft.fc = nn.Linear(num_ftrs, D_out)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = torch.optim.Adam(model_ft.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model, losses, accuracies = train_val_model(model_ft, criterion, optimizer_ft,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=25, log_interval=5)
epochs = np.arange(len(losses['train']))
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['val'], '--r')
Epoch 0/24
----------
train Loss: 1.0622 Acc: 0.6341
val Loss: 0.8539 Acc: 0.7066
Epoch 5/24
----------
train Loss: 0.5674 Acc: 0.8073
val Loss: 0.5792 Acc: 0.8019
Epoch 10/24
----------
train Loss: 0.3416 Acc: 0.8803
val Loss: 0.4313 Acc: 0.8577
Epoch 15/24
----------
train Loss: 0.2898 Acc: 0.8980
val Loss: 0.4491 Acc: 0.8608
Epoch 20/24
----------
train Loss: 0.2792 Acc: 0.9014
val Loss: 0.4352 Acc: 0.8631
Training complete in 147m 23s
Best val Acc: 0.863800
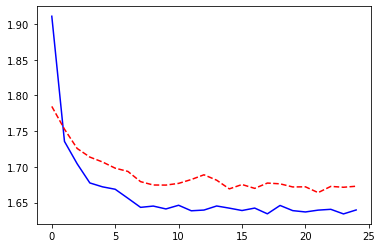
ResNet as a feature extractor¶
Freeze all the network except the final layer:
requires_grad == False to freeze the parameters so that the
gradients are not computed in backward().
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, D_out)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model, losses, accuracies = train_val_model(model_conv, criterion, optimizer_conv,
dataloaders, scheduler=exp_lr_scheduler, num_epochs=25, log_interval=5)
epochs = np.arange(len(losses['train']))
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['val'], '--r')
Epoch 0/24
----------
train Loss: 1.9108 Acc: 0.3277
val Loss: 1.7846 Acc: 0.3804
Epoch 5/24
----------
train Loss: 1.6686 Acc: 0.4170
val Loss: 1.6981 Acc: 0.4146
Epoch 10/24
----------
train Loss: 1.6462 Acc: 0.4267
val Loss: 1.6768 Acc: 0.4210
Epoch 15/24
----------
train Loss: 1.6388 Acc: 0.4296
val Loss: 1.6752 Acc: 0.4226
Epoch 20/24
----------
train Loss: 1.6368 Acc: 0.4325
val Loss: 1.6720 Acc: 0.4240
Training complete in 42m 23s
Best val Acc: 0.429600
Adam optimizer
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, D_out)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.Adam(model_conv.fc.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model, losses, accuracies = train_val_model(model_conv, criterion, optimizer_conv,
exp_lr_scheduler, dataloaders, num_epochs=25, log_interval=5)
epochs = np.arange(len(losses['train']))
_ = plt.plot(epochs, losses['train'], '-b', epochs, losses['val'], '--r')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-dde92868b554> in <module>
19
20 model, losses, accuracies = train_val_model(model_conv, criterion, optimizer_conv,
---> 21 exp_lr_scheduler, dataloaders, num_epochs=25, log_interval=5)
22
23 epochs = np.arange(len(losses['train']))
TypeError: train_val_model() got multiple values for argument 'num_epochs'