Introduction to Machine Learning¶
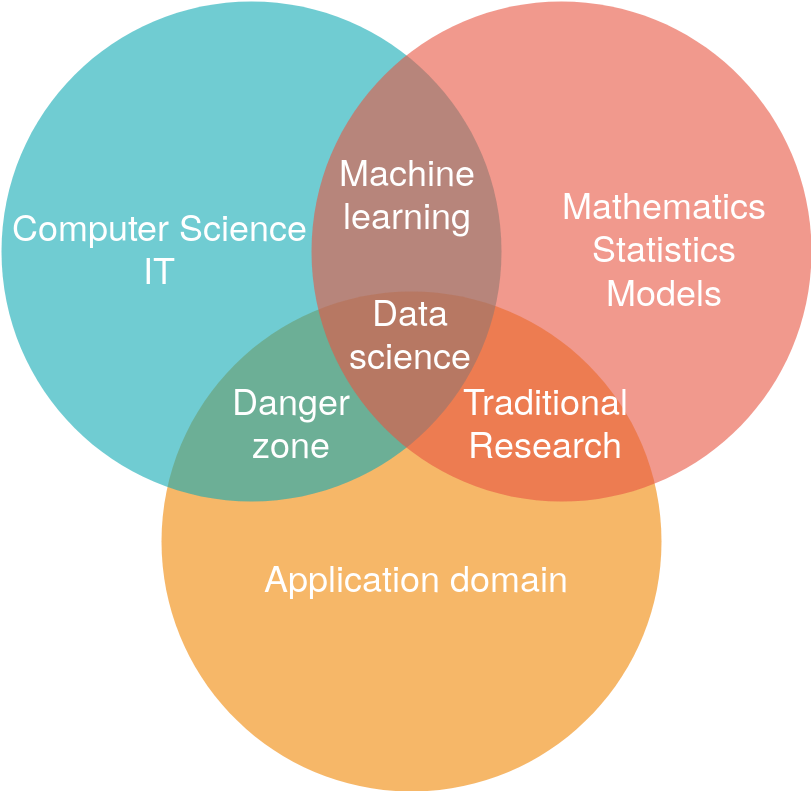
Machine learning within data science¶
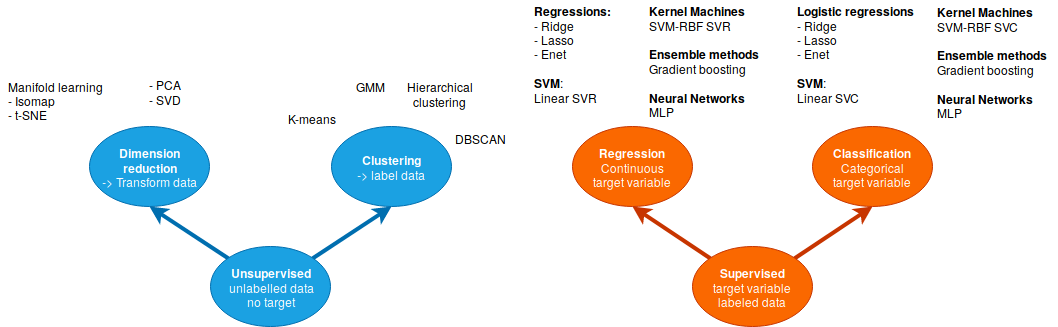
Machine learning covers two main types of data analysis:
Exploratory analysis: Unsupervised learning. Discover the structure within the data. E.g.: Experience (in years in a company) and salary are correlated.
Predictive analysis: Supervised learning. This is sometimes described as “learn from the past to predict the future”. Scenario: a company wants to detect potential future clients among a base of prospects. Retrospective data analysis: we go through the data constituted of previous prospected companies, with their characteristics (size, domain, localization, etc…). Some of these companies became clients, others did not. The question is, can we possibly predict which of the new companies are more likely to become clients, based on their characteristics based on previous observations? In this example, the training data consists of a set of n training samples. Each sample, \(x_i\), is a vector of p input features (company characteristics) and a target feature (\(y_i \in \{Yes, No\}\) (whether they became a client or not).
IT/computing science tools¶
High Performance Computing (HPC)
Data flow, data base, file I/O, etc.
Python: the programming language.
Numpy: python library particularly useful for handling of raw numerical data (matrices, mathematical operations).
Pandas: input/output, manipulation structured data (tables).
Statistics and applied mathematics¶
Linear model.
Non parametric statistics.
Linear algebra: matrix operations, inversion, eigenvalues.
Data analysis methodology¶
- Formalize customer’s needs into a learning problem:
- A target variable: supervised problem.
Target is qualitative: classification.
Target is quantitative: regression.
- No target variable: unsupervised problem
Vizualisation of high-dimensional samples: PCA, manifolds learning, etc.
Finding groups of samples (hidden structure): clustering.
- Ask question about the datasets
Number of samples
Number of variables, types of each variable.
- Define the sample
For prospective study formalize the experimental design: inclusion/exlusion criteria. The conditions that define the acquisition of the dataset.
For retrospective study formalize the experimental design: inclusion/exlusion criteria. The conditions that define the selection of the dataset.
In a document formalize (i) the project objectives; (ii) the required learning dataset (more specifically the input data and the target variables); (iii) The conditions that define the acquisition of the dataset. In this document, warn the customer that the learned algorithms may not work on new data acquired under different condition.
Read the learning dataset.
Sanity check (basic descriptive statistics); (ii) data cleaning (impute missing data, recoding); Final Quality Control (QC) perform descriptive statistics and think ! (remove possible confounding variable, etc.).
Explore data (visualization, PCA) and perform basic univariate statistics for association between the target an input variables.
Perform more complex multivariate-machine learning.
Model validation using a left-out-sample strategy (cross-validation, etc.).
Apply on new data.